Unsupervised Learning Assignment Help (Get Instant Unsupervised Learning Homework Help)

- Analytica Assignment Help
- AWS Assignment Help
- ConnectMath Assignment Help
- ERP Assignment Help
- EViews Assignment Help
- Excel Assignment Help
- Information Technology Assignment Help
- JMP Assignment Help
- Keras Assignment Help Online
- LabVIEW Assignment Help
- LISREL Assignment Help
- MATLAB Assignment Help
- MegaStat Assignment Help
- Minitab Assignment Help
- MYOB Assignment Help
- Power BI Assignment Help
- Python Assignment Help
- R Programming Assignment Help
- R Shiny Assignment Help
- SAS Assignment Help
- Software Engineering Assignment Help
- SPSS Amos- SEM Assignment Help
- SPSS Assignment Help
- SQL Assignment Help
- STATA Assignment Help
- Statistics Assignment Experts
- Statistix Assignment Help
- Tableau Assignment Help
- TensorFlow Assignment Help
- XLSTAT Assignment Help
- Advanced Probability Theory Assignment Help
- ANOVA Assignment Help
- Applied Statistics Assignment Help
- Bayesian Statistics Assignment Help
- Black Scholes Theory Assignment Help
- Blockchain Technology Assignment Help
- C++ Assignment Help
- Calculus Assignment Help
- Chi-square Testing Assignment Help
- Cluster Analysis Assignment Help
- CNN Assignment Help
- Computer Architecture Assignment Help
- Confidence Intervals Assignment Help
- Control Charts Assignment Help
- Correlation Analysis Assignment Help
- Cyber Security Assignment Help
- Data Analysis Assignment Help
- Data Classification Assignment Help
- Database Management Assignment Help
- Decision Theory Assignment Help
- Decision Tree Assignment Help
- Descriptive Statistics Assignment Help
- Distribution Theory Assignment Help
- Factor Analysis Assignment Help
- Game Theory Assignment Help
- Hypothesis Testing Assignment Help
- Kalman & Particle Filter Assignment Help
- Linear Algebra Assignment Help
- Linear Discriminant Analysis Assignment Help
- Linear Programming Assignment Help
- Logistics Regression Assignment Help
- Markov Processes Assignment Help
- Mathematical Methods Assignment Help
- MATLAB GUI Assignment Help
- Monte Carlo simulation Assignment Help
- Multivariate Analysis Assignment Help
- Multivariate Statistics Assignment Help
- Neural Networks Assignment Help
- Nonparametric Tests Assignment Help
- Numerical Methods in MATLAB
- Operating System Assignment Help
- Principal Component Analysis Assignment Help
- Probability Assignment Help
- Probability Distributions Assignment Help
- Psychology Statistics Assignment Help
- Regression Analysis Assignment Help
- Sampling Assignment Help
- Statistical Inference Assignment Help
- Stochastic Processes Assignment Help
- Survey Methodology Assignment Help
- Time Series Assignment Help
- Time Series Homework Help
- Artificial Intelligence Assignment Help
- Backpropagation Assignment Help
- Big Data Assignment Help
- Business Analytics Assignment Help
- C Programming Assignment Help
- Chatbot Assignment Help
- Clinical Psychology Assignment Help
- Clinical Trials Assignment Help
- Coding Assignment Help
- Computer Networking Assignment Help
- Computer Science Assignment Help
- Computer Vision Assignment Help Online
- Consumer Behavior Assignment Help
- Control Systems Using MATLAB
- Data Analytics Assignment Help
- Data Flow Diagram Assignment Help
- Data Mining Assignment Help
- Data Science Assignment Help
- Deep Learning Assignment Help
- Derivatives Assignment Help
- Digital Signal Processing in MATLAB
- Econometrics Assignment Help
- Finance Assignment Help
- Finance Insurance Assignment Help
- Financial Risk Analysis Assignment Help
- Financial Statistics Assignment Help
- Fixed Income Markets Assignment Help
- Flask Assignment Help
- Forecasting Financial Time Series
- Image Processing in MATLAB
- Machine Learning Assignment Help
- Math Assignment Help
- MATLAB in Computing
- MyStatLab Quiz Help
- Natural Language Processing Assignment Help
- Network Design in MATLAB
- Neural Networks Assignment Help
- Operations Research Assignment Help
- Programming Assignment Experts
- Project Management Assignment Help
- Quantitative Psychology Assignment Help
- Random Forest Assignment Help
- Reinforcement Learning Assignment Help
- Statistics Dissertation Help
- Supervised Learning Assignment Help
- Support Vector Machine Assignment Help
- Take My R Programming Exam
- Unsupervised Learning Assignment Help
- ANOVA Homework Help
- Computer Science Homework Help
- Data Mining Homework Help
- Java Homework Help
- MyMathlab Quiz Help
- Neural Networks Homework Help
- Online Calculus Exam Help
- Online Computer Engineering Exam Help
- Online Math Exam Help
- Online Programming Exam Helper
- Online Python Exam Help
- Online Statistics Exam Helper
- Pay Someone To Take Statistics Exam
- Proctored Exam Help
- R Programming Homework Help
- Statistics Homework Help
- Take My GED Test Online
- Take My Online Exam
- Take My Psychology Quiz
- Take My Statistics Quiz
- Take my Statistics Test
- Accounting Assignment Writers in the US
- Accounting Dissertation Help
- Accounting Research Paper Help
- Activity Based Accounting Assignment Help
- Auditing Assignment Help
- Balance Sheet Analysis Assignment Help
- Behavioral Finance Assignment Help
- Business Valuation Assignment Help
- Capital Budgeting Assignment Help
- Cost Accounting Assignment Help
- Demand Forecast Assignment Help
- Economics Cost Curves Assignment Help
- Financial Accounting Assignment Help
- Financial Accounting Exam Help
- Financial Reporting Assignment Help
- Financial Statement Analysis Assignment Help
- Forensic Accounting Assignment Help
- Fund Accounting Assignment Help
- International Finance Assignment Help
- Managerial Accounting Assignment Help
- Mergers and Acquisitions Assignment Help
- Online Economics Exam Help
- Online Finance Exam Help
- Public Economics Assignment Help
- Solve My Accounting Paper
- Statistics Research Paper Help
- Take My Cost Accounting Exam
- Take My Managerial Accounting Exam
- Tax Accounting Assignment Help
- Python Assignment Help Australia
- Python Assignment Help Canada
- Python Assignment Help UK
- Python Assignment Help USA
- Statistics Assignment Help Australia
- Statistics Assignment Help Canada
- Statistics Assignment Help Hong Kong
- Statistics Assignment Help Ireland
- Statistics Assignment Help New Zealand
- Statistics Assignment Help Qatar
- Statistics Assignment Help Saudi Arabia
- Statistics Assignment Help Singapore
- Statistics Assignment Help UK
- Statistics Assignment Help USA
- Statistics Project Help
Order Now
Why Choose The Statistics Assignment Help?
On Time Delivery
Plagiarism Free Service
24/7 Support
Affordable Pricing
PhD Holder Experts
100% Confidentiality

I am so grateful for your timely completion of my Unsupervised Learning Assignment and I hope the other two follow suit. I will fill out the feedback as soon as possible in appreciation of your speedy work and hopefully the results of the assignment in the future as well.
I hired such an excellent writing team because I was worried about my grades in the assignment. They were responsive throughout the process and provided me with an excellent document. Thanks a lot!
I've come across the Statistics Assignment Help as being one of the best writing services I've encountered online. They provided professional assistance at an affordable price, and were particular about the details in the academic paper.
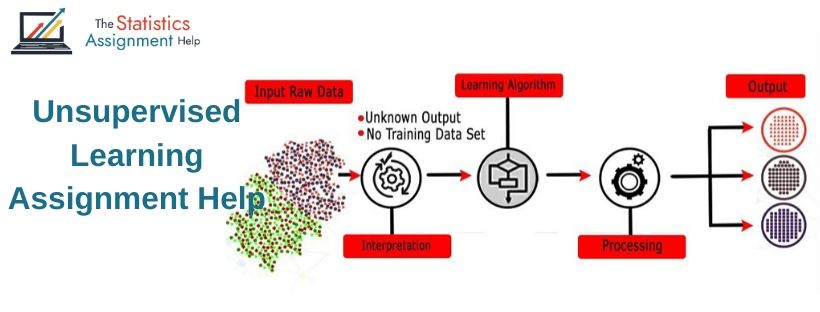
Unsupervised Learning Assignment Help Online
Are you stressed about solving a long list of assignments in a short time period? Then, you can seek the help of our experts who possess in-depth experience and knowledge in solving machine-learning assignments, especially on unsupervised learning. The machine-learning experts will refer to the requirements given by your professors and gather the information. Consequently, they solve the paper in a comprehensive way that helps you secure the best grades in the examination. You can get rid of the pressure and stress of solving data science assignments. Be the topic simple or complicated, our experts are best to offer non-unsupervised learning assignments to students in the US, UK, Australia, and other countries.
For students pursuing a degree in machine learning, assignments are a critical aspect of their education. With the increasing demand for machine learning professionals, the competition is tough, and students must excel in their coursework to stand out. That’s why many students opt for Unsupervised Learning Assignment Help to ensure they get the best possible grades and to secure their future in the field. With a team of experts in the field, students can be sure that their assignments are in good hands and that they will receive the best possible grades.
What Is Unsupervised Learning?
Unsupervised learning is a type of machine learning technique where do must not supervise any model rather you should let the model work by itself to find the information. This type of technique would deal with data that is not labeled. Unsupervised learning algorithms are used to process intricate jobs compared to supervised learning. This type of technique is not anticipated compared to the natural learning methods that are available. Many students including the brilliant ones find it tough to solve unsupervised learning assignments in a short time. It takes a lot of time for the student to research, understand, and complete the assignment. So, students who do not want to lose grades in their examinations would seek the help of experts. Our experienced experts offer the best Unsupervised learning assignment help and help you secure an A+ grade on the assignments.
The assignments solved by our experts can also be used as study material to learn in-depth about unsupervised learning concepts.
The best example of unsupervised learning is a baby playing with its pet. The baby knows how the dog looks. If a few weeks later, if the relatives bring their pet, the baby would be able to identify the animal based on its features though it has not seen the same dog before. This has 2 years, of eyes, and walks like its pet. The baby would identify the animal to be a dog. This unsupervised learning is something where you will not teach the machine anything rather it will learn from the data. If it is supervised learning, then the family friend must have told the baby that it is a dog.
Why use Unsupervised Learning?
Key reasons why professionals use unsupervised learning
- Unsupervised learning will find various kinds of patterns in the data.
- Unsupervised techniques can be used to find various features that let you categorize the information.
- The unsupervised learning happens in real-time so the data that is given would be thoroughly analyzed and given a label.
- It is quite easy to get the data that is not unlabeled over the labeled data where it needs a lot of manual intervention.
Different Types of Unsupervised Learning
The unsupervised learning would have clustering and association issues.
Clustering: This is the main concept that a student has to learn thoroughly when using unsupervised learning. This helps you to find the right structure and pattern while collecting the uncategorized data. Clustering algorithms will thoroughly process the data and find the groups if they are already there in the data. You can easily modify the clusters that the algorithms should use to identify. This lets you adjust the granularity of the group.
There are different clustering types that are used:
- Exclusive (partitioning): In this type of method, one data would be categorized in such a way that one data belongs to a single cluster. The best example of this type of cluster is k-means.
- Agglomerative: In this type of technique, every piece of data is considered to be a single cluster. The iterative unions between the clusters that are close by would cut down the total number of clusters. The best example of this type of clustering is hierarchical clustering.
- Overlapping: In this type of clustering technique, the fuzzy set would be used to cluster the information. Every point would be categorized into one or multiple clusters with a unique degree of membership. The data is given a unique membership value. The best example of it is Fuzzy C means. If you have to solve the assignment on this topic and lack knowledge, you can seek the help of our Statistics and Data Science experts. They are available round the clock to offer you the required help. The assignment offered will help the students to secure the best grades in the examination.
- Probabilistic: This technique will use the probability distribution that would create clusters. These keywords are categorized into shoe, glove, man, and women.
Type of Clustering
The following types of clustering are available include:
- Hierarchical clustering: Hierarchical clustering is a kind of algorithm that would build clusters in a particular hierarchy. This starts with the data that belongs to its own cluster. There are two key clusters that would be the same cluster. This algorithm will stop functioning when there is only one cluster that is left. If you are finding it challenging to solve the assignment on this topic, you can take the help of our experts. They will solve a well-researched and informative assignment that help you score good grades in the examination.
- K-means clustering: K means is an iterative clustering algorithm that lets you find the top value in every iteration phase. First, the total number of clusters would be selected. In this type of technique, the data points are clustered together to form k groups. When the K is large, it means to have small groups with high granularity whereas if the k is lower, then the groups will have low granularities. The output given for the algorithm is labelled as a group. This will assign a key data point to one of the k groups. If you find it tough to solve the assignment on this topic, you can take the help of our experts. They solve the assignments while letting you leave with peace.
- Association: The rules that are defined would help you to form an association between the data points that are in the huge database. This unsupervised learning technique is widely used to establish relationships between various variables and huge datasets. For instance, patients who are prone to cancer are categorized based on their gene establishment.
Unsupervised Learning Assignment Help Topics
Unsupervised learning encompasses several topics, including:
- Clustering: Clustering is a technique that groups similar data points together. This approach is useful for identifying customer segments, grouping similar products and finding similar data points in large datasets.
- Dimensionality Reduction: Dimensionality reduction is a technique that reduces the number of variables in a data set while preserving its structure and relationships. This approach is useful for simplifying complex datasets and for visualizing high-dimensional data.
- Anomaly Detection: Anomaly detection is a technique that identifies data points that are significantly different from the rest of the data set. This approach is useful for detecting fraud, outliers, and other unusual data points.
- Association Rule Mining: Association rule mining is a technique that identifies relationships between variables in a dataset. This approach is useful for discovering relationships between products, customers, and other variables in the data set.
- Non-Negative Matrix Factorization (NMF): NMF is a technique that reduces the dimensionality of a dataset while preserving its structure and relationships. This approach is useful for finding underlying patterns in the data and for reducing the complexity of the data.
Unsupervised Assignment Help
We are offering superior quality unsupervised assignment help to students globally at pocket-friendly prices. Be you lack time, knowledge, solving skills, or research skills, you can seek our expert help at any point in time. We are ever ready to solve an assignment that is 100 accurate and free from plagiarism.
Why Students Should Choose UnSupervised Assignment Help Services?
We are the best in the market offering the following benefits to the students availing of our services:
- Free from plagiarism: The solutions prepared by our experts are unique and run through the plagiarism test to check the content's originality. We also send this report to the students.
- Experts in machine learning: We have experts who have hands-on and academic experience in teaching machine learning to solve your assignments flawlessly.
If you want a perfect machine learning assignment as per your professor’s requirements, you can call us immediately.